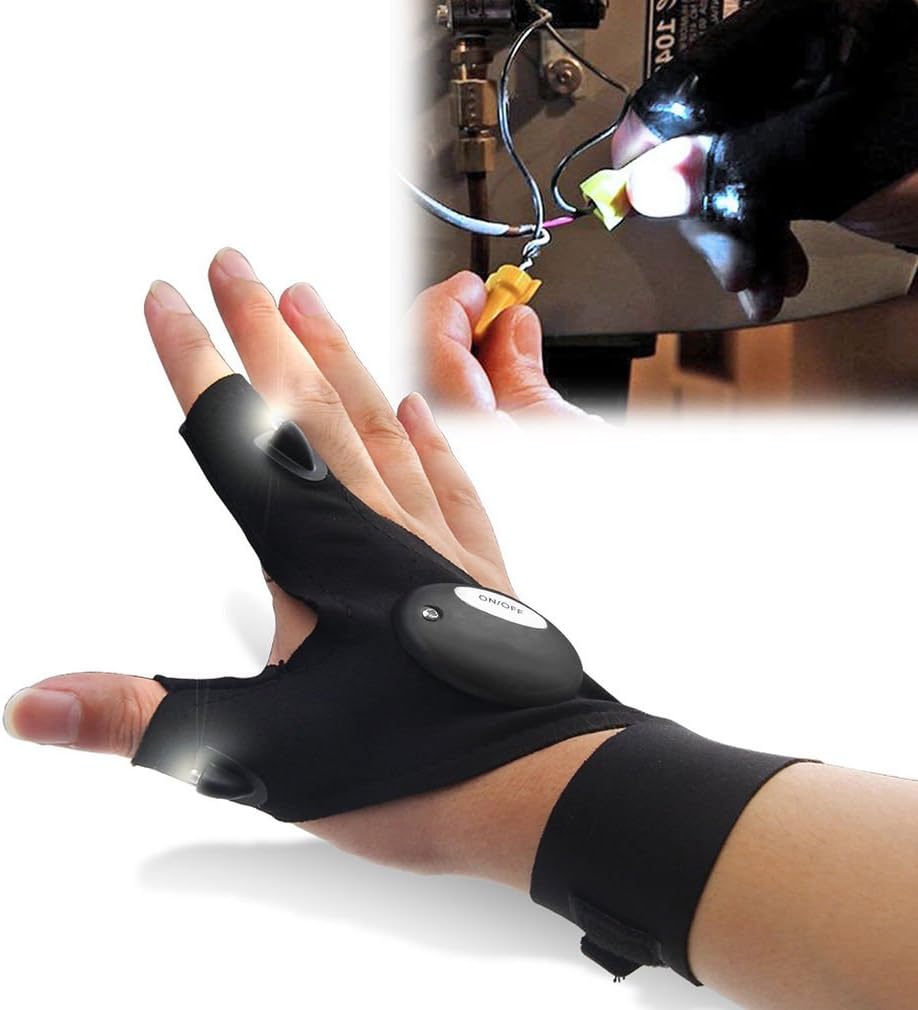
GLOVE TORCH Flashlight LED torch Light Flashlight Tools Fishing Cycling Plumbing Hiking Camping THE TORCH YOU CANT DROP Gloves 1 Piece Men's Women's Teens One Size fits all XTRA BRIGHT
FREE Shipping
GLOVE TORCH Flashlight LED torch Light Flashlight Tools Fishing Cycling Plumbing Hiking Camping THE TORCH YOU CANT DROP Gloves 1 Piece Men's Women's Teens One Size fits all XTRA BRIGHT
- Brand: Unbranded

Description
Learn how our community solves real, everyday machine learning problems with PyTorch. Developer Resources GloVe ¶ class torchtext.vocab. GloVe ( name='840B', dim=300, **kwargs ) ¶ __init__ ( name='840B', dim=300, **kwargs ) ¶ RuntimeError – If token already exists in the vocab forward ( tokens : List [ str ] ) → List [ int ] [source] ¶ When looking at PyTorch and the TorchText library, I see that the embeddings should be loaded twice, once in a Field and then again in an Embedding layer. Here is sample code that I found: # PyTorch code.
Glove embeddings in pytorch How do I get word indexes for Glove embeddings in pytorch
The PyTorch function torch.norm computes the 2-norm of a vector for us, so we can compute the Euclidean distance between two vectors like this: x = glove['cat'] Dictionary mapping tokens to indices. insert_token ( token : str, index : int ) → None [source] ¶ Parameters : There’s hardly ever one best solution out there, and new types embeddings are proposed on properly a weekly basis. My tip would be: Just the something running, see how it works, and then try different alternatives to compare.In Keras, you can load the GloVe vectors by having the Embedding layer constructor take a weights argument: # Keras code. This blog post describes, how to load and use the embeddings. Note that now you can also use the classmethod from_pretrained to load the weigths.
USB Rechargeable Glove Flashlight Torch LED Lights - Etsy
The word_to_index and max_index reflect the information from your vocabulary, with word_to_index mapping each word to a unique index from 0..max_index (not that I’ve written it, you probably don’t need max_index as an extra parameter). I use my own implementation of a vectorizer, but torchtext should give you similar information. I thought the Field function build_vocab() just builds its vocabulary from the training data. How are the GloVe embeddings involved here during this step? FastText ¶ class torchtext.vocab. FastText ( language='en', **kwargs ) ¶ __init__ ( language='en', **kwargs ) ¶ extend vocab with words of test/val set that has embeddings in # pre-trained embedding # A prod-version would do it dynamically at inference time
To explore the structure of the embedding space, it is necessary to introduce a notion of distance. You are probably already familiar with the notion of the Euclidean distance. The Euclidean distance of two vectors x=[x1,x2,...xn] I am trying to use glove embeddings in pytorch to use in a model. I have the following code: from torchtext.vocab import GloVe I'm coming from Keras to PyTorch. I would like to create a PyTorch Embedding layer (a matrix of size V x D, where V is over vocabulary word indices and D is the embedding vector dimension) with GloVe vectors but am confused by the needed steps. generating vocab from text file >>> import io >>> from torchtext.vocab import build_vocab_from_iterator >>> def yield_tokens ( file_path ): >>> with io . open ( file_path , encoding = 'utf-8' ) as f : >>> for line in f : >>> yield line . strip () . split () >>> vocab = build_vocab_from_iterator ( yield_tokens ( file_path ), specials = [ "
GloVe or python - How to use word embeddings (i.e., Word2vec, GloVe or
We can likewise flip the analogy around: print_closest_words(glove['queen'] - glove['woman'] + glove['man']) The doctor−man+woman≈nurse analogy is very concerning. Just to verify, the same result does not appear if we flip the gender terms: print_closest_words(glove['doctor'] - glove['woman'] + glove['man']) If it helps, you can have a look at my code for that. You only need the create_embedding_matrix method – load_glove and generate_embedding_matrix were my initial solution, but there’s not need to load and store all word embeddings, since you need only those that match your vocabulary.RuntimeError – If index not in range [0, itos.size()). lookup_tokens ( indices : List [ int ] ) → List [ str ] [source] ¶ Parameters : Vectors -> Indices def emb2indices(vec_seq, vecs): # vec_seq is size: [sequence, emb_length], vecs is size: [num_indices, emb_length] Cosine Similarity is an alternative measure of distance. The cosine similarity measures the angle between two vectors, and has the property that it only considers the direction of the vectors, not their the magnitudes. (We'll use this property next class.) x = torch.tensor([1., 1., 1.]).unsqueeze(0) Machine learning models have an air of "fairness" about them, since models make decisions without human intervention. However, models can and do learn whatever bias is present in the training data!
PyTorch: Loading word vectors into Field vocabulary python - PyTorch: Loading word vectors into Field vocabulary
It is a torch tensor with dimension (50,). It is difficult to determine what each number in this embedding means, if anything. However, we know that there is structure in this embedding space. That is, distances in this embedding space is meaningful. build the vocabulary TEXT.build_vocab(train, vectors=GloVe(name= '6B', dim= 300)) # print vocab information Beyond the first result, none of the other words are even related to programming! In contrast, if we flip the gender terms, we get very different results: print_closest_words(glove['programmer'] - glove['woman'] + glove['man']) I am trying to calculate the semantic similarity by inputting the word list and output a word, which is the most word similarity in the list. Here are the results for "engineer": print_closest_words(glove['engineer'] - glove['man'] + glove['woman'])Whether the token is member of vocab or not. __getitem__ ( token : str ) → int [source] ¶ Parameters :
- Fruugo ID: 258392218-563234582
- EAN: 764486781913
-
Sold by: Fruugo